Come individuare gli outliers con Excel
By VALUE4YOU
Published On March 28, 2023
of Davide Bruno
Business Analyst and Content Creator
COME INDIVIDUARE GLI OUTLIERS CON EXCEL
Per capire il post di oggi serve subito ripassare le parole outlier e quartile.
Outlier è un termine utilizzato per definire, in un insieme di osservazioni, un valore anomalo ossia un valore chiaramente distante dalle altre osservazioni disponibili.
I quartili sono quei valori/modalità che ripartiscono la popolazione in quattro parti di uguale numerosità.
Tornando alla vita lavorativa quotidiana, capita di dover importare un set di dati e naturalmente di non poterli vedere singolarmente, sfruttando una regola statistica base ed Excel, proviamo oggi a individuare quegli eventuali valori che possono falsare le nostre analisi e portarci fuori strada quando studiamo un set di dati.
Per l’esercizio di oggi individuare gli outliers abbiamo bisogno di sei cose:
- il data set;
- il primo quartile;
- il terzo quartile;
- il range interquartile;
- il limite inferiore accettabile;
- il limite superiore accettabile.
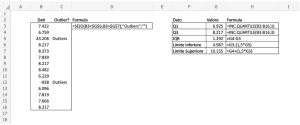
Il data set l’ho inventato come da figura sotto.

Ovviamente ora saltano subito all’occhio i valori 43.206 e -928 che sono effettivamente fuori scala, proprio perché il numero dei valori è limitato.
Per trovare tutti gli altri elementi mancanti creiamo una tabellina dedicata che riepilogo con l’immagine in fondo al post.
Per trovare il primo e il terzo quartile possiamo usare la funzione Excel =INC.QUARTILE().
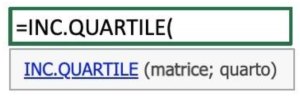
Con questa funzione faremo riordinare ad Excel tutti i valori del data set in ordine crescente e troveremo il valore al di sotto del quale si trova il 25% (nel caso del primo quartile, Q1) e poi il 75% (nel caso del terzo quartile, Q3) dei dati.
Gli argomenti della funzione sono:
- matrice, che usiamo per indicare dove si trova il data set;
- quarto, che utilizziamo per indicare il quartile di riferimento (per trovare il primo quartile metteremo 1 e successivamente per il terzo quartile metteremo 3).
Per individuare il range interquartile IQR dobbiamo sottrarre il Q1 al Q3.
Il range interquartile può essere inteso come il range di valori accettabile oltre Q1 e Q3.
IQR è quindi il valore da sommare al Q3 e sottrarre al Q1 per trovare rispettivamente il limite inferiore accettabile ed il limite superiore accettabile.
Inoltre possiamo vedere IQR come il 50% intermedio dei valori accettabili, dato dal 75% (cioè Q3) – il 25% (cioè il Q1).
Troviamo infine i due limiti, quello superiore e quello inferiore, ovvero i limiti oltre i quali i valori sono da considerarsi outliers.
Per trovare il limite inferiore e superiore, faremo rispettivamente Q1-(1,5*IQR) e Q3+(1,5*IQR).
Per finire torniamo nel data set e sotto la colonna Outlier?, per ogni valore, dobbiamo fare un confronto fra il singolo valore del data set e i due limiti trovati prima.
Per il confronto creiamo una semplice formula composta da SE e O, come da immagine sotto.
Se il valore del data set in esame è superiore al limite superiore o inferiore al limite inferiore, abbiamo trovato un outlier e la formula lo riporterà chiaramente.
Ecco quindi che dopo aver trascinato la formula “rivelatrice degli outliers” dalla prima linea del data set fino all’ultima, avremo individuato tutti gli eventuali valori anomali.
Con quanto fatto finora abbiamo creato un modellino dinamico da riutilizzare in futuro.
Accanto al data set, al posto della colonna Formula che serve solo per chiarire i passaggi del post, sarebbe meglio mettere una colonna denominata Nota per fornire eventuali spiegazioni sui valori, perché non è detto che siano sempre errori.
Spesso, in alternativa al metodo sopra, che mi rendo conto essere un minimo laborioso, per risparmiare tempo e fatica ho visto fare la media del data set, moltiplicare questa la media ottenuta per una data percentuale (ad es. 5/10%) e considerare errore tutto ciò che supera (in positivo e in negativo) quest’ultimo valore.
Tu come individui gli outlier? Lo fai mai?
